This project aims to create the largest ground truth fake news analysis dataset for real and fake news content in relation to social media posts. Below illustrates the major contributions of the TruthSeeker dataset to the current fake news dataset landscape:
One of the most extensive benchmark datasets with more than 180,000 labelled Tweets.
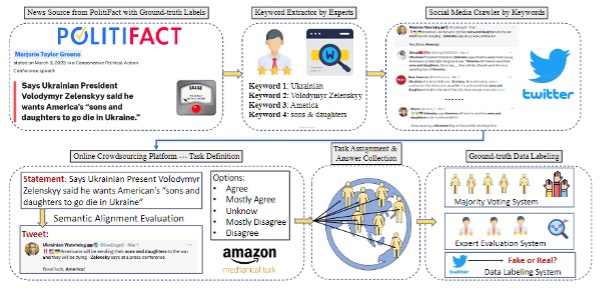
The data for the Truth Seeker and Basic ML dataset were generated through the crawling of tweets related to Real and Fake news from the Politifact Dataset. Taking these ground truth values and crawling for tweets related to these topics (by manually generating keywords associated with the news in question to input into the twitter API), we were able to extract over 186,000 (before final processing) tweets related to 700 real and 700 fake pieces of news.
Taking this raw tweet data, we then used crowdsourcing in the form of Amazon Mechanical Turk to generate a majority answer to how closely the tweet agrees with the Real/Fake news source statement. After, a majority agreement algorithm is employed to designate a validity to the associated tweets in both a 3 and 5 category classification column.
This results in one of the largest ground truth datasets for fake news detection on twitter ever created. The TruthSeeker Dataset. Then we also generated a dataset of features from the tweet itself and the metadata of the user who posted the related tweet. Allowing the user to have the option to use both deep learning models as well as classical machine learning techniques.
| Name | Description |
|---|---|
| unique count | number of unique, complex words |
| total count | total number of words |
| ORG percent | Percent of text including spaCy ORG tags |
| NORP percent | Percent of text including spaCy NORP tags |
| GPE percent | Percent of text including spaCy GPE tags |
| PERSON percent | Percent of text including spaCy PERSON tags |
| MONEY percent | Percent of text including spaCy MONEY tags |
| DATA percent | Percent of text including spaCy DATA tags |
| CARDINAL percent | Percent of text including spaCy CARDINAL tags |
| PERCENT percent | Percent of text including spaCy PERCENT tags |
| ORDINAL percent | Percent of text including spaCy FAC tags |
| LAW percent | Percent of text including spaCy LAW tags |
| PRODUCT percent | Percent of text including spaCy PRODUCT tags |
| EVENT percent | Percent of text including spaCy EVENT tags |
| TIME percent | Percent of text including spaCy TIME tags |
| LOC percent | Percent of text including spaCy LOC tags |
| ORG percent | Percent of text including spaCy ORG tags |
| WORK OF ART percent | Percent of text including spaCy WOA tags |
| QUANTITY percent | Percent of text including spaCy QUANTITY tags |
| LANGUAGE percent | Percent of text including spaCy LANGUAGE tags |
| Max Word | length of the longest word in the sentence |
| Min Word | length of the shortest word in the sentence |
| Avg Word Length | average length of words in the sentence |
| Name | Description |
|---|---|
| present verb | number of present tense verbs |
| past verb | number of past tense verbs |
| adjectives | number of adjectives |
| pronouns | number of pronouns |
| TO’s | number of to usages |
| determiners | number of determiners |
| conjunctions | number of conjunctions |
| dots | number of (.) used |
| exclamations | number of (!) used |
| question | number of (?) used |
| ampersand | number of (&) used |
| capitals | Number of capitalized letters |
| quotes | number of quotation makes used |
| digits | number of digits (0-9) used |
| long word freq | number of long words |
| short word freq | number of short words |
| Name | Description |
|---|---|
| followers count | number of followers |
| friends count | number of friends |
| favourites count | number of favourites across all tweets |
| statuses count | number of tweets |
| listed count | number of tweets the user has in lists |
| mentions | number of times the user was mentioned |
| quotes | number of times the user has been quote tweeted |
| replies | number of replies the user has |
| retweets | number of retweets the user has |
| favourites | number of favourites the user has |
| hashtags | number of hashtags the user has used |
| URLs | whether the user has a provided a url in relation to their profile |
| BotScoreBinary | Binary score whether the user is considered a bot or not |
| cred | credibility score |
| normalized influence | influence score the user has, normalized |
The feature only dataset contains textual and lexical information related to each tweet. As well as metadata information about the user of said tweet. All in all providing over 50 features for training on any classical machine learning model, rather than more advanced deep learning algorithms.
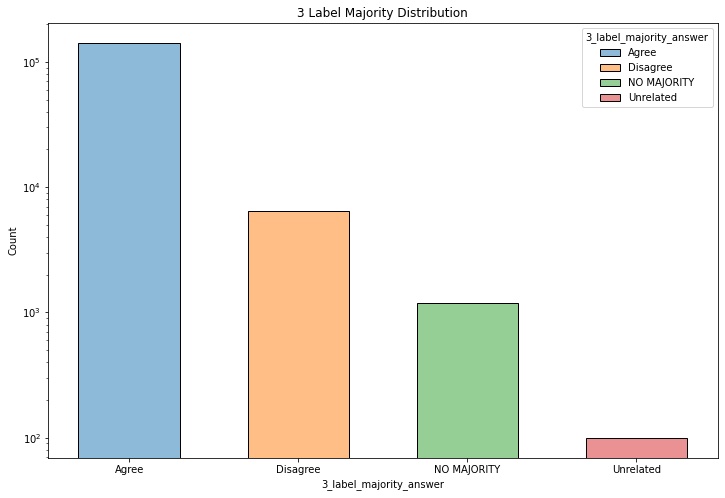
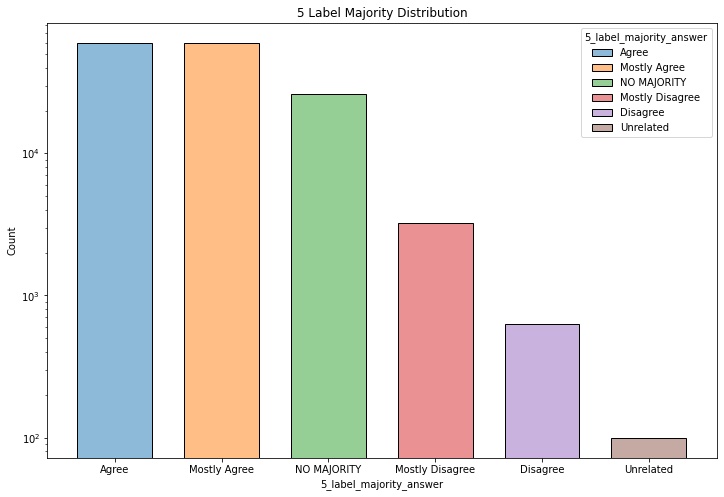
3 label majority answers 5 label majority answers
The TruthSeeker dataset contains the aforementioned tweets, the source statement of news in which the keywords used to source the tweets were created from, the manual keywords of the source statement, the 5 label majority answer of the truthfulness value, and the 3 label majority answer.
This dataset provides the opportunity for training deep learning BERT based models on a large corpus of crowdsourced ground truth tweets. Allowing for fine grain 5 label classification (4 if unknowns are removed) or more general 3 label classification (binary if unknowns are removed). The associated paper shows the possible conversion table that can be used to then assign truthfulness values to the individual tweets.
The main dataset directory (TruthSeeker2023) contains two separate .csv files:
Features_For_Traditional_ML_Techniques
| Name | Description |
|---|---|
| unique_count | number of unique, complex words |
| total_count | total number of words |
| ORG_percent | Percent of text including spaCy ORG tags |
| NORP_percent | Percent of text including spaCy NORP tags |
| GPE_percent | Percent of text including spaCy GPE tags |
| PERSON_percent | Percent of text including spaCy PERSON tags |
| MONEY_percent | Percent of text including spaCy MONEY tags |
| DATA_percent | Percent of text including spaCy DATA tags |
| CARDINAL_percent | Percent of text including spaCy CARDINAL tags |
| PERCENT_percent | Percent of text including spaCy PERCENT tags |
| ORDINAL_percent | Percent of text including spaCy ORDINAL tags |
| FAC_percent | Percent of text including spaCy FAC tags |
| LAW_percent | Percent of text including spaCy LAW tags |
| PRODUCT_percent | Percent of text including spaCy PRODUCT tags |
| EVENT_percent | Percent of text including spaCy EVENT tags |
| TIME_percent | Percent of text including spaCy TIME tags |
| LOC_percent | Percent of text including spaCy LOC tags |
| ORG_percent | Percent of text including spaCy ORG tags |
| WORK_OF_ART_percent | Percent of text including spaCy WOA tags |
| QUANTITY_percent | Percent of text including spaCy QUANTITY tags |
| LANGUAGE_percent | Percent of text including spaCy LANGUAGE tags |
| Max Word | Length of the longest word in the sentence |
| Min Word | Length of the shortest word in the sentence |
| Avg Word Length | Average length of words in the sentence |
| present_verb | Number of present tense verbs |
| past_verb | Number of past tense verbs |
| adjectives | Number of adjectives |
| pronouns | Number of pronouns |
| TO’s | Number of to usages |
| determiners | Number of determiners |
| conjunctions | Number of conjunctions |
| dots | Number of (.) used |
| exclamations | Number of (!) used |
| question | Number of (?) used |
| ampersand | Number of (&) used |
| capitals | Number of capitalized letters |
| digits | Number of digits (0-9) used |
| long_word_freq | Number of long words |
| short_word_freq | Number of short words |
| followers_count | Number of followers |
| friends_count | Number of friends |
| favourites_count | Number of favourites across all tweets |
| statuses_count | Number of tweets |
| listed_count | Number of tweets the user has in lists |
| mentions | Number of times the user was mentioned |
| replies | Number of replies the user has |
| retweets | Number of retweets the user has |
| favourites | Number of favourites the user has |
| hashtags | Number of hashtags (#) the user has used |
| URLs | whether the user has a provided a url in relation to their profile |
| quotes | Number of times the user has been quote tweeted |
| BotScoreBinary | Binary score whether the user is considered a bot or not |
| cred | Credibility score |
| normalized_influence | Influence score the user has, normalized |
| majority_target | Truth value of the tweet |
| statement | Headline of a new article |
| BinaryNumTarget | Binary representation of the statement's truth value (1 = True / 0 = False) |
| tweet | Twitter posts related to the associated manual keywords |
| Name | Description |
|---|---|
| author | The author of the statement |
| statement | Headline of a new article |
| target | The groundtruth value of the statement |
| BinaryNumTarget | Binary representation of the target value (1 = True / 0 = False) |
| manual_keywords | Manually created keywords used to search twitter with |
| tweet | Twitter posts related to the associated manual keywords |
| 5_label_majority_answer | Majority answer using 5 labels (Agree, Mostly Agree, Disagree, Mostly Disagree, Unrelated) *NO MAJORITY indicates that there was no consensus when a majority answer was generated. |
| 3_label_majority_answer | Majority answer using 3 labels (Agree, Disagree, Unrelated) *NO MAJORITY indicates that there was no consensus when a majority answer was generated. |
The project is not currently in development, but any contribution is welcome. Please contact one of the authors of the paper.
The authors would like to thank the Canadian Institute for Cybersecurity for its financial and educational support.
To learn more about why this dataset was created, watch this video, "Defending Democracy: Combatting Information Disorder by Sajjad Dadkhah."
S. Dadkhah, X. Zhang, A. G. Weismann, A. Firouzi and A. A. Ghorbani, "The Largest Social Media Ground-Truth Dataset for Real/Fake Content: TruthSeeker," in IEEE Transactions on Computational Social Systems, 99. 1-15, Oct. 2023.
{kind=link}
{kind=link}
{kind=link}