A Unified Multi-Format Dataset for Phishing and Quishing Attachment Detection
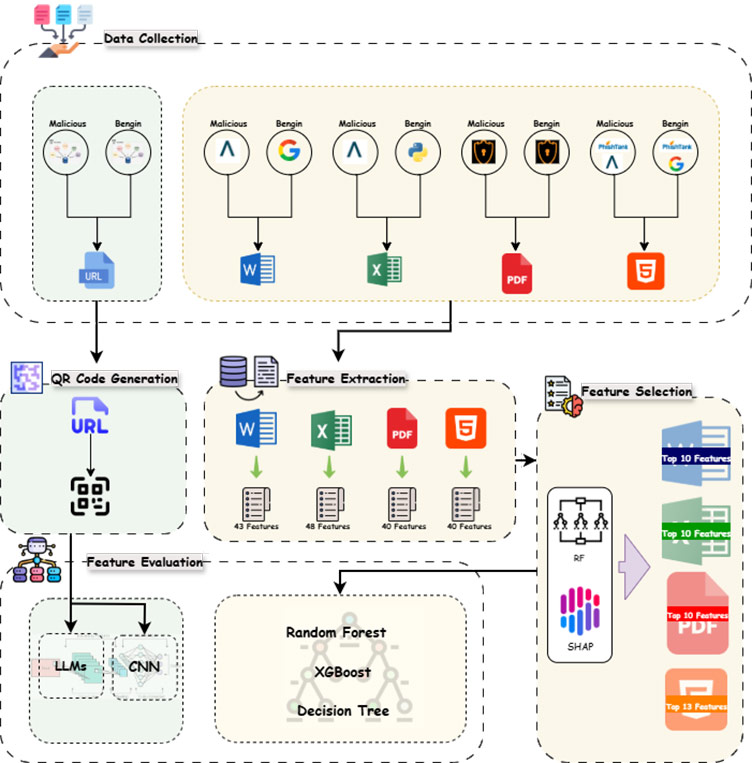
This dataset provides the first comprehensive benchmark for detecting malicious attachments and QR code-based phishing (Quishing) used in phishing attacks. It covers five high-risk attachment formats widely leveraged by adversaries in phishing campaigns: Microsoft Word, Excel, PDF files, HTML pages, and QR codes to provide a heterogeneous foundation for developing, evaluating, and comparing detection mechanisms.
For each file format, the dataset contains balanced benign and malicious samples systematically collected from verified repositories complemented with benign samples obtained via controlled web crawling as well as synthetically generated document files. For the four document-based formats (Word, Excel, PDF, HTML), static feature extraction pipelines were designed to capture structural, content-level without requiring file execution, thereby enabling safe offline analysis.
To enhance model interpretability and efficiency, two-stage feature ranking (combining SHAP analysis and feature importance) was employed to select the most discriminative attributes, resulting in 10 selected features for Word, Excel, and PDF, and 13 features for HTML. These features were evaluated using lightweight classifiers (Random Forest, XGBoost, Decision Tree), demonstrating consistently high detection performance across formats while preserving computational scalability.
For the QR-code subset, over one million images were generated from malicious and benign URLs, two complementary methods were utilized: an image-based detection, leveraging Convolutional Neural Networks (CNNs) to capture spatial and structural distortions in QR-patterns; and lexical analysis of decoded URLs using recent distilled transformer models (BERT-Tiny, DeBERTa-v3, ModernBERT, DeepSeek-R1).
This dataset aims to bridge the gap between academic research and real-world phishing attack defense by enabling machine learning, deep learning, and explainable AI methods to be tested on realistic, heterogeneous document types.
| Type | Benign samples | Malicious samples | Total | Features extracted | Features selected |
|---|---|---|---|---|---|
| Word | 10,000 | 10,000 | 20,000 | 43 | 10 |
| Excel | 10,000 | 10,000 | 20,000 | 48 | 10 |
| 10,000 | 10,000 | 20,000 | 40 | 10 | |
| HTML | 10,000 | 10,000 | 20,000 | 40 | 13 |
| QR Code | 430,000 | 575,000 | 1,000,000 | Image-based CNN | - |
| URL Strings | 433,918 | 614,656 | 1,048,576 | Transformer models (lexical URL analysis) | - |
The authors would like to thank the Canadian Institute for Cybersecurity for financial and technical support in building this dataset. The authors also sincerely acknowledge the external repositories and open intelligence sources that facilitated the collection and validation of this dataset.