Domain Name System (DNS) is one of the early and vulnerable network protocols which has several security loopholes that have been exploited repeatedly over the years. DNS abuse has always been an area of great concern for cybersecurity researchers. However, providing security and privacy to DNS requests and responses is still a challenging task as attackers use sophisticated attack methodologies to steal data on the fly.
To overcome some of the DNS vulnerabilities related to privacy and data manipulation, IETF introduced DNS over HTTPS (DoH) in RFC8484, a protocol that enhances privacy and combats eavesdropping and man-in-the-middle attacks by encrypting DNS queries and sending them in a covert channel/tunnel so that data is not hampered on the way. Nonetheless, unavailability of a representative dataset is the key obstacle to evaluate the techniques that capture DoH traffic in a network topology.
This research work proposes a systematic approach to generate a typical dataset to analyze, test, and evaluate DoH traffic in covert channels and tunnels. The main objective of this project is to deploy DoH within an application and capture benign as well as malicious DoH traffic as a two-layered approach to detect and characterize DoH traffic using time-series classifier.
The final dataset includes implementing DoH protocol within an application using five different browsers and tools and four servers to capture Benign-DoH, Malicious-DoH and non-DoH traffic. Layer 1 of the proposed two-layered approach is used to classify DoH traffic from non-DoH traffic and layer 2 is used to characterize Benign-Doh from Malicious-DoH traffic. The browsers and tools used to capture traffic include Google Chrome, Mozilla Firefox, dns2tcp, DNSCat2, and Iodine while the servers used to respond to DoH requests are AdGuard, Cloudflare, Google DNS, and Quad9.
In CIRA-CIC-DoHBrw-2020 dataset, a two-layered approach is used to capture benign and malicious DoH traffic along with non-DoH traffic. To generate the representative dataset, HTTPS (benign DoH and non-DoH) and DoH traffic is generated by accessing top 10k Alexa websites, and using browsers and DNS tunneling tools that support DoH protocol respectively. At the first layer, the captured traffic is classified as DoH and non-DoH by using statistical features classifier. At the second layer, DoH traffic is characterized as benign DoH and malicious DoH by using time-series classifier.
Non-DoH: Traffic generated by accessing a website that uses HTTPS protocol is captured and labeled as non-DoH traffic. In order to capture ample traffic to balance the dataset, thousands of websites from Alexa domain are browsed.
Benign-DoH: Benign DoH is non-malicious DoH traffic generated using the same technique as mentioned in non-DoH by using Mozilla Firefox and Google Chrome web browsers.
Malicious-DoH: DNS tunneling tools such as dns2tcp, DNSCat2, and Iodine are used to generate malicious DoH traffic. These tools can send TCP traffic encapsulated in DNS queries. In other words, these tools create tunnels of encrypted data. Therefore, DNS queries are sent using TLS-encrypted HTTPS requests to special DoH servers.
A notion of packet clumps is used to reduce the dimensionality of data and remove insignificant packets such as acknowledgements and packets too small to carry data. A clump of packets is defined as a sequence of one or more consecutive packets of a network flow (having the same source and destination) in the same direction to create a new and succinct representation of our data. The rationale for this step is to combine these packets to find the application traffic scattered between several packets in the process of TLS segmentation and IP fragmentation. A threshold timeout value for clumps is also considered so that two packets with a greater time difference do not end up in the same packet clump.
It is imperative to mention that malicious traffic can be tunneling as well as non-tunneling but only tunneled malicious traffic is generated for this research.
The network diagram used to capture the traffic for the dataset is presented in Figure 1. Firstly, normal web browsing activity that includes non-DoH HTTPS and benign DoH is simulated using web browsers. Secondly, malicious DoH is generated by a combination of tools used to create DoH tunnels. Traffic generated by all these tools is captured for pre-processing and training the classifiers.
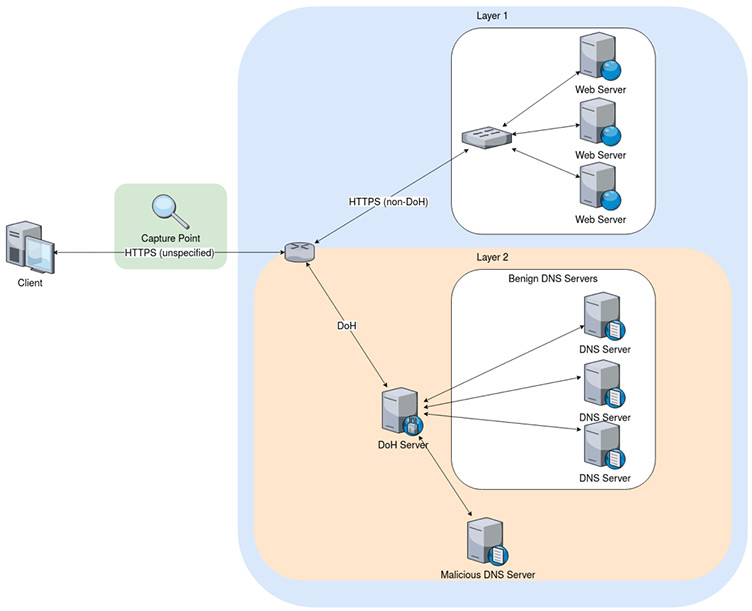
Figure 1: Network topology used to capture
As clearly seen from Figure 1, we set up web servers to capture layer 1 data, and benign DNS servers, malicious DNS server and DoH server to capture data at layer 2. The web browsers were configured to use various public DoH resolvers. To connect to Firefox, we also used GeckoDriver which is an intermediary between Firefox and tools that interacts with Firefox. Similarly, for Google Chrome, we used chrome driver to communicate with the browser. Traffic is captured between the DoH proxy and DoH server using tcpdump.
We developed DoHLyzer, a DoH traffic flow generator and analyzer for anomaly and attack detection and characterization. DoHLyzer is a script written in python that uses Scapy to read pcap files or sniff packets online.
A tool named DoH Data Collector is developed to simulate different DoH tunneling scenarios and capture the resulting HTTPS traffic. In each instance of simulation, a new DoH tunnel is made over the underlying network according to different parameters used in a scenario such as:
To generate enough data, the clients used in the simulation were run simultaneously on 10 servers, all connecting to a single C2 server posing as a DNS nameserver. A central controller based on another server controls the timing of simulations. Table 1 lists the IP addresses used to generate non-DoH, benign DoH and malicious DoH traffic at both layers of the project methodology.
Table 1: IP addresses used to generate traffic
| Destination IPs used for accessing public DoH servers (all TLS packets to these hosts are DoH packets): |
1.1.1.1 8.8.4.4 8.8.8.8 9.9.9.9 9.9.9.10 9.9.9.11 176.103.130.131 176.103.130.130 149.112.112.10 149.112.112.112 104.16.248.249 104.16.249.249 |
| Source IP used to connect to websites (Google Chrome): |
192.168.20.191 |
| Source IPs used to connect to websites (Mozilla Firefox): |
192.168.20.111 192.168.20.112 192.168.20.113 |
| Source IPs used to create DoH tunnels: |
192.168.20.144 192.168.20.204 192.168.20.205 192.168.20.206 192.168.20.207 192.168.20.208 192.168.20.209 192.168.20.210 192.168.20.211 192.168.20.212 |
Based on the defined scenario in previous section, we implemented the infrastructure and captured the traffic. Table 2 presents the details of packets and flows captured by using browsers/tools and DoH servers.
Table 2: Dataset details
| Browser/tool | DoH Server | Packets | Flows | Type |
|---|---|---|---|---|
|
Google Chrome |
AdGuard Cloudflare Google DNS Quad9 |
5609K 6117K 5878K 10737K |
105141 132552 108680 199090 |
HTTPS (Non-DoH and Benign DoH) |
|
Mozilla Firefox |
AdGuard Cloudflare Google DNS Quad9 |
4943K 4299K 6413K 4956K |
50485 90260 138422 92670 |
|
|
dns2tcp |
AdGuard Cloudflare Google DNS Quad9 |
1281K 3694K 28711K 8750K |
5459 6045 17423 138588 |
Malicious DoH
|
|
DNSCat2 |
AdGuard Cloudflare Google DNS Quad9 |
1301K 12346K 48069K 9309K |
5369 9230 11915 9108 |
|
|
Iodine |
AdGuard Cloudflare Google DNS Quad9 |
3938K 5932K 73459K 22668K |
11336 14110 12192 8975 |
DoHMeter is a tool developed in Python to extract statistical and time-series features from the captured PCAP files. It produces a CSV file as output. The data in that file is labeled flow-wise based on the IP addresses of the servers used in the network diagram (Figure 1). Table 3 lists the 28 statistical features extracted from captured traffic.
Table 3: List of extracted statistical traffic features
| Parameter | Feature |
|---|---|
| F1 | Number of flow bytes sent |
| F2 | Rate of flow bytes sent |
| F3 | Number of flow bytes received |
| F4 | Rate of flow bytes received |
| F5 | Mean Packet Length |
| F6 | Median Packet Length |
| F7 | Mode Packet Length |
| F8 | Variance of Packet Length |
| F9 | Standard Deviation of Packet Length |
| F10 | Coefficient of Variation of Packet Length |
| F11 | Skew from median Packet Length |
| F12 | Skew from mode Packet Length |
| F13 | Mean Packet Time |
| F14 | Median Packet Time |
| F15 | Mode Packet Time |
| F16 | Variance of Packet Time |
| F17 | Standard Deviation of Packet Time |
| F18 | Coefficient of Variation of Packet Time |
| F19 | Skew from median Packet Time |
| F20 | Skew from mode Packet Time |
| F21 | Mean Request/response time difference |
| F22 | Median Request/response time difference |
| F23 | Mode Request/response time difference |
| F24 | Variance of Request/response time difference |
| F25 | Standard Deviation of Request/response time difference |
| F26 | Coefficient of Variation of Request/response time difference |
| F27 | Skew from median Request/response time difference |
| F28 | Skew from mode Request/response time difference |
If you want to use the AI techniques to analyze, you can download our generated data (CSV) file and analyze the network traffic. If you want to use a new feature extractor, you can use the raw captured files (PCAP) to extract your features. And then, you can use the data mining techniques for analyzing the generated data.
YouTube video: DNS over HTTPS by Dr. Gurdip Kaur
You may redistribute, republish, and mirror the CIRA-CIC-DoHBrw-2020 dataset in any form. However, any use or redistribution of the data must include a citation to DoHMeter and the following research paper outlining the details of captured DoH traffic:
Mohammadreza MontazeriShatoori, Logan Davidson, Gurdip Kaur, and Arash Habibi Lashkari, “Detection of DoH Tunnels using Time-series Classification of Encrypted Traffic”, The 5th IEEE Cyber Science and Technology Congress, Calgary, Canada, August 2020
If you are interest in CIRA-CIC-DoHBrw-2020, you may also be interested in the BCCC-CIRA-CIC-DoHBrw-2020 dataset made available by our colleagues at the Behaviour-Centric Cybersecurity Center, York University.